import java.util.*;
public class Main
{
public static void main(String[] args)
{
int[] array = new int[5];
System.out.println(array);
}
}위의 코드를 실행시키면
[I@44a5eaa
와 같은 값이 출력됩니다.
이 값은 무엇을 뜻하는 걸까요?
참조형 변수
자바에서 기본형 변수 이외의 모든 변수는 참조형 변수로 참조형 변수는 객체의 주소값을 저장하고 있습니다. array라는 변수도 마찬가지로 정수형 배열이 저장되어 있는 주소를 담고 있습니다.
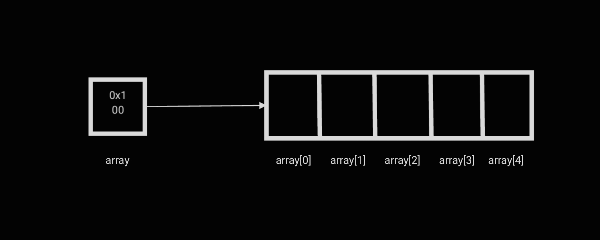
위 그림과 같이 말이죠
하지만 자바에서는 주소에 직접 접근하는 것은 막고 있기 때문에 메모리 주소 값은 아닙니다.
@앞의 [I는 클래스 식별자로 해당 객체가 integer 형의 배열이라는 것을 가리킵니다. @뒤의 44a5eaa는 해시코드를 16진수로 변환한 것으로 객체의 고유한 값을 나타냅니다. 해당 객체의 해시코드를 반환해 주는 hashCode() 메서드와 출력 결과를 비교해 보면
import java.util.*;
public class Main
{
public static void main(String[] args)
{
int[] array = new int[5];
System.out.println(array);
System.out.println(array.hashCode());
}
}[I@44a5eaa
71982762
로 44a5eaa(16) = 72982762(10)인 것을 알 수 있습니다. 그렇다면 대체 해시코드란 무엇일까요?
해시코드
해시코드란 객체마다의 고유한 정수 값으로 객체를 구분하고 해시 테이블과 같은 자료구조에서 빠르게 검색하도록 해주는 고유값입니다. 고유값이라면 해당 객체의 주소를 기반으로 해시코드를 도출할까?라는 생각이 들어 찾아본 결과
https://github.com/openjdk/jdk/blob/master/src/hotspot/share/runtime/synchronizer.cpp
static inline intptr_t get_next_hash(Thread* current, oop obj) {
intptr_t value = 0;
if (hashCode == 0) {
// This form uses global Park-Miller RNG.
// On MP system we'll have lots of RW access to a global, so the
// mechanism induces lots of coherency traffic.
value = os::random();
} else if (hashCode == 1) {
// This variation has the property of being stable (idempotent)
// between STW operations. This can be useful in some of the 1-0
// synchronization schemes.
intptr_t addr_bits = cast_from_oop<intptr_t>(obj) >> 3;
value = addr_bits ^ (addr_bits >> 5) ^ GVars.stw_random;
} else if (hashCode == 2) {
value = 1; // for sensitivity testing
} else if (hashCode == 3) {
value = ++GVars.hc_sequence;
} else if (hashCode == 4) {
value = cast_from_oop<intptr_t>(obj);
} else {
// Marsaglia's xor-shift scheme with thread-specific state
// This is probably the best overall implementation -- we'll
// likely make this the default in future releases.
unsigned t = current->_hashStateX;
t ^= (t << 11);
current->_hashStateX = current->_hashStateY;
current->_hashStateY = current->_hashStateZ;
current->_hashStateZ = current->_hashStateW;
unsigned v = current->_hashStateW;
v = (v ^ (v >> 19)) ^ (t ^ (t >> 8));
current->_hashStateW = v;
value = v;
}
value &= markWord::hash_mask;
if (value == 0) value = 0xBAD;
assert(value != markWord::no_hash, "invariant");
return value;
}
위의 오픈 JDK의 코드를 요약해 보자면 해시코드를 생성하는 방법에는
0. A randomly generated number.
1. A function of memory address of the object.
2. A hardcoded 1 (used for sensitivity testing.)
3. A sequence.
4. The memory address of the object, cast to int.
5. Thread state combined with xorshift (https://en.wikipedia.org/wiki/Xorshift)
6가지 방법이 있는 것을 알 수 있습니다.
그중 디폴트 방법으로 JDK8부터는 5번 방법을 사용합니다.
https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/87ee5ee27509/src/share/vm/runtime/globals.hpp#l1127
product(intx, hashCode, 5, "(Unstable) select hashCode generation algorithm")찾아본 많은 자료에서 해시함수가 메모리의 주소를 기반으로 만들어졌다며 마치 주소처럼 사용하는 자료들이 많이 있었는데, 이는 항상 사실이 아님을 알 수 있습니다.
이러한 해쉬코드를 얻을 수 있는 메서드가 하나 더 있습니다. 바로 System.identityhashCode(obj)인데요 둘의 차이는 무엇일까요?
identityHashCode
두 메서드 모두 해시코드를 반환한다는 점은 동일하지만 hashCode가 Object 클래스에 정의되어 각각의 클래스에 맞게 오버라이드 할 수 있다면 identityHashCode는 System 클래스에 정의되어 오버라이드 할 수 없다는 특징이 있습니다. Object의 hashCode() 메소드는 하위 클래스에서 오버라이드가 가능하기 때문에 객체마다 유일한 값을 갖고 있지 않습니다. 객체의 특성이 동일하다는 것을 표현하기 위해 이 메서드를 오버라이드할 수 있습니다. System.identityHashCode()는 오버라이드가 안되며 객체의 고유한 hashCode를 리턴합니다. 때문에 객체 자체를 비교하려면 이 메소드를 사용하는 것이 좋습니다.
참고로 오버라이드 하지 않았다면 hashCode와 identityHashCode의 리턴값은 같습니다.
hashCode가 오버라이드 되어 있는 대표적인 클래스가 String 클래스인데요
String str1 = "Hello";
String str2 = "Hello";
String str3 = new String("Hello");
System.out.println("str1 hashCode ? " + str1.hashCode());
System.out.println("str2 hashCode ? " + str2.hashCode());
System.out.println("str3 hashCode ? " + str3.hashCode());위의 코드를 실행해 보면 모두 같은 해시코드를 가지고 있는 것을 알 수 있습니다.
str1 hashCode ? 69609650
str2 hashCode ? 69609650
str3 hashCode ? 69609650str1과 str2는 같은 주소를 가지고 있는 객체라 같을 수 있지만(문자열 리터럴의 경우 메모리에 동일한 값이 있으면 동일한 데이터를 참조합니다.) str3은 둘과 엄연히 다른 객체임에도 같은 해시코드를 가지고 있는 것을 볼 수 있습니다. 왜냐하면 아래와 같이 값이 같으면 같은 해시코드를 가지도록 오버라이드 됐기 때문입니다.
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}그런데 아래의 코드를 실행해 보면
import java.util.*;
public class Main
{
public static void main(String[] args)
{
String str1 = "Hello";
String str2 = new String("Hello");
System.out.println(str1.equals(str2));
System.out.println(str1 == str2);
}
}true
false
가 나오는 것을 알 수 있습니다. Object.equals() 함수의 원본이
public boolean equals(Object obj){
return (this == obj);
}로 결국은 똑같은 코드라고 생각할 수 있겠지만 equals() 메서드 또한 String 클래스에서 참조값이 아닌 문자열 값으로 비교하도록 오버라이딩 됐기 때문입니다. String 클래스와 같이 equals()와 hashCode() 메서드는 함께 오버라이딩 해줘야 합니다.
equals/hashCode 오버라이딩
hashCode의 경우 int형으로 값을 반환하기 때문에 범위가 한정되어 있습니다. 그에 따라 다른 객체임에도 해시코드가 같을 수 있는데요(해시충돌) 그러면 객체를 서로 정확히 구분할 수 없지 않나?라는 생각이 드실 수도 있습니다. 하지만 자바에서 hash 값을 사용하는 Collection(HashMap, HashSet, HashTable)은 객체가 논리적으로 같은지 비교할 때 해시코드가 같은지 비교 후 equals를 통해 주소값을 직접 2차적으로도 비교도 합니다.
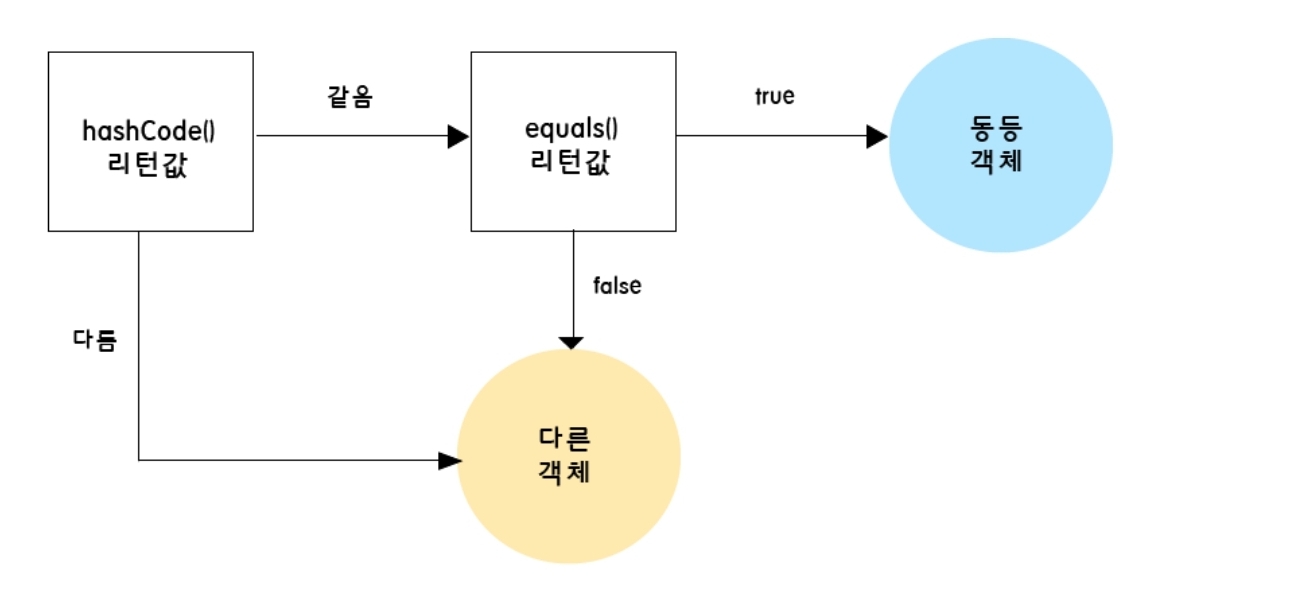
위의 흐름처럼 객체를 비교하기 때문에 hashCode나 equals의 비교 기준이 하나만 바뀌면 논리적으로 예상치 못한 결과를 낳을 수 있기 때문에 오버라이딩을 할 경우 두 메서드를 동시에 오버라이딩 해야 합니다.
틀린 부분이 있다면 지적해주시면 감사하겠습니다.
'개발 > Java' 카테고리의 다른 글
| [Java] 지네릭스(generics) (0) | 2024.05.25 |
|---|---|
| [Java] 인터페이스(Interface) (0) | 2024.05.15 |
| [Java] 오토 박싱 & 오토 언박싱 (1) | 2024.02.27 |
| [Java]부동소수점수(2진 체계의 부호 표현법) (0) | 2023.12.16 |